
保存容量を抑えるために、ファイルサーバーやバックアップ、アーカイブでも『重複排除』機能が利用されていることをご存知の方は多いと思います。それでも、あなたは、このような疑問を持ったことはありませんか?
「重複排除で、データ容量はどのくらい減るのかな?」
「重複排除をしているはずなのに、いまいち、効果がないような気がする」
「重複排除機能を使うと、サーバーのスペックが落ちるって聞いたことがあるけど、本当かな?」
企業内では同一データやドキュメントの世代保管など、重複したデータが案外多く存在しています。例えば、社内メールでドキュメントを添付すれば、送信先の数だけ重複したデータが生成されます。データの増加に合わせてストレージ容量を拡張し続けることは、IT予算を圧迫するばかりですね。重複排除機能を採用すれば、バックアップやアーカイブの際に、ストレージ容量を抑えることができるでしょう。
重複データを検出する単位はどうでしょう?単位によって効果が得られやすくなる可能性はあります。
そもそも、重複排除ってどこで実行されているのでしょうか。実行のタイミングによっては、システムパフォーマンスの維持や、ネットワーク回線の圧迫を軽減こともできます。
機能を追加するので、どこかしらに負荷がかかることは避けられませんが、負荷箇所を事前に知ることで対策をとることができるのではないでしょうか。
ここでは、バックアップでの『重複排除』について、仕組みから単位、方式など効果事例を含めて、詳しくご案内します。
目次
1.重複排除とは
重複排除とは、データの中身を分析し、同じデータがあればそれを取り除く機能です。利用先によって、目的や効果が全く異なります。
◆ 重複排除の2つの目的と効果
1) アプリケーションやデータベースで利用する『重複排除』
目的: *ユニーク(一意の)データを抽出する。
効果: 検索の操作性やデータの正確性を高め、適切な情報を早く入手できる。
解説: ExcelやAccessでは関数やマクロ、実装されている機能を使うなどして、重複データの検索値を任意で設定し、
排除します。そしてそのアプリケーション、またはデータベース内で実行されます。
2) バックアップやアーカイブ等で利用する『重複排除』
目的: 対象データを検証し、重複データを排除する
効果: ストレージの無駄を省き、コストを削減。保存にかかる時間や転送量削減効果も期待できる。
解説: ソフトウェアかハードウェアで実装、用意された単位で、サーバーや保存先などで実行されます。
De-duplicationと表記され、『デ・デュプリケーション』『デデュープ』と表現されます。
一般的には10~50%のストレージ容量削減効果があると言われています。
*ユニーク(英:Unique)とは
「他に類のない」「唯一無二の」「比類ない」という意味。IT分野では、重複を取り除いた、一意の、唯一の、固有の、といった意味で使用されます。
| 利用場所 | アプリケーションやデータベースなど | バックアップやアーカイブなど |
| 目的 | データをユニークにする | 重複するデータを排除する |
| 効果 | 検索の操作性や情報の正確性を高め、 適切な情報を早く入手できる | ストレージ容量とコストを削減、 転送量も削減できる場合がある |
| 検索条件 | 無限:任意で設定可能 | 有限:ファイル、ブロックなどの単位がある |
| 実装元 | そのアプリケーション、またはデータベース内 | ソフトウェア、またはハードウェア |
| 実行場所 | そのアプリケーション、またはデータベース内 | サーバー、ストレージなど方式によって異なる |
バックアップでの重複排除では、大容量のデータをいかに保管していくか、多くの企業が抱える課題に対し、データ保存量を削減することで課題解消の一翼を担っています。また、データの転送前での重複排除では、転送データ量が削減されネットワークの負荷を軽減します。
◆ 重複排除機能を取り入れるべきケースのご紹介
ケース1:バックアップ先のストレージ容量を抑えたい場合
重複排除で複数の同じデータをひとつにして保存できれば、ストレージ容量の削減が可能です。
コスト節減にもつながります。
ケース2:容量課金制のクラウドにバックアップデータを保存している場合
重複排除でストレージ容量の削減ができれば、ストレージにかかるコストも節減できます。
ケース3:遠隔地へのデータ転送が必要な場合
転送前に重複排除でデータ量を削減すれば、回線を圧迫せず、バックアップによるネットワークトラブルを回避できます。
ケース4:バックアップにかかる時間を短縮させたい場合
ストレージに書き込むデータ量を重複排除で削減すれば、ストレージパフォーマンスを維持し、バックアップ時間超越回避につながります。
2.重複排除機能の仕組み
重複排除は、ソフトウェアかハードウェアで実装され、殆どの場合、データをブロック単位に分割します。各データブロックの重複を検出、重複データブロックは除外し、重複ではない新規と判断したデータブロックをストレージに保存するまでを自動的に処理します。この「検出」「排除」のタイミングは3パターン(方式)あります。
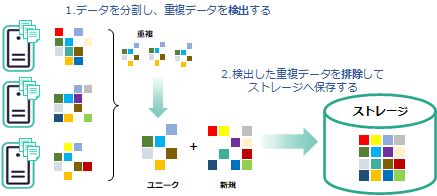
それでは、単位から重複の判定方法、重複排除の3つの方式と順にみていきましょう。
3.重複排除を実行する単位
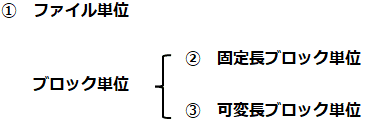
データの重複を判断するための粒度、いわゆる「単位」には、「ファイル単位」と「ブロック単位」があります。
更に、ブロック単位では、「固定長」と「可変長」に分かれ、合計3つが代表的な単位になります。
重複排除機能が、どの単位でもって行われているかで効果は大きく変わります。

注意:音声や映像、画像、暗号化されたデータなどでは、あまり重複排除の効果が出ないケースが多いです。
導入前には実環境でテストを行い、重複排除の効果を確認することをお勧めします。
3-1 ファイル単位
ファイル単位の重複排除は、もっとも単純な方式であり、シングルインスタンスと呼ばれることもあります。
1文字だけでも情報が変更されていると、そのファイル自体が新しいデータとして扱われます。
ファイルサーバー上に複数人が同じファイルを保存するなど、重複ファイルがストレージ内に多く存在する場合は、大きな効果を発揮します。
3-2 ブロック単位 (固定長と可変長)
ファイルの構成要素であるブロック単位に分割し、重複データかどうかを判断する方式です。
ブロックサイズは、ファイルよりも細かい単位で重複を見つけることができます。
同じブロックは排除され、内容が異なるブロックだけを新しいデータとして扱います。
ファイル単位ではできなかったファイルバージョン間の重複排除を行うことができ、重複排除の削減率が高くなります。
3-2-1 固定長ブロック単位
固定長ブロック単位では、データパターンと関係なく、決められた長さ毎にデータをブロックに格納します。
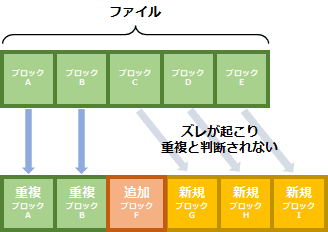
例えば、別名で保存されたファイルや、ファイル名を変更したファイルは重複データと判断しますが、ファイルの途中にデータが追加されると、データを分割するポイントが変わり、それ以降のブロックが同じデータであっても、別のデータとして認識します。
ファイルシステムではよく利用される単位です。
3-2-2 可変長ブロック単位
可変長のブロック単位では、データパターンを参照しながらブロックサイズを調整します。
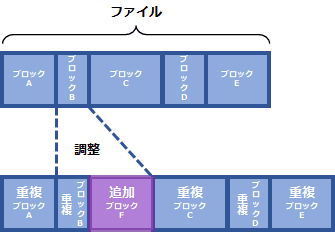
ブロックの切り分け位置は、固定長とは異なり先頭からの長さではなく、データパターンに基づいている為、ファイルの途中にデータが追加されてもブロックサイズを調整し、重複データを適切に認識することができます。
重複排除の削減率が最も高い単位です。バックアップでは多くの場合、可変長ブロック単位が採用されます。
4.重複の判定方法
では、どのような方法で重複を判断するのでしょうか。主に3つ判定方法をご紹介します。
①データ自体を突き合わせて比較する方法
②*ハッシュ関数(*チェックサム)で比較後、重複データを突き合わせて再度比較する方法
③暗号学的ハッシュ関数で比較をする方法
*ハッシュ関数とは
入力されたデータに一定の手順で計算を行い、入力値の長さによらずあらかじめ決められた固定長の出力データを得る関数。
この場合、同じデータからは常に同じハッシュ値が得られ、どのような長さの入力もすべて同じ長さ(実用上は数バイトから数十バイト程度が多い)のハッシュ値を得る。ハッシュ値は元のデータの特徴を表す短い符号として利用することができ、データの比較や検索を高速化することができる。
参照:IT用語辞典より、「ハッシュ関数 【hash function】 メッセージダイジェスト関数」
*チェックサムとは
ハッシュ関数の一種であり、誤り検出符号の一つで、データ列を整数値の列とみなして和を求め、これをある定数で割った余り(余剰)を検査用データとするもの。最も単純な誤り検出方式の一種で、誤りの検出精度は低いが原理が簡単で容易に実装でき、計算コストも低いため、簡易な誤り検出方式として広く普及している。
参照:IT用語辞典より、「チェックサム 【checksum】 チェックサムチェック / checksum check」
4-1 データ自体を突き合わせて比較する方法
もっとも単純で基本的な方法ですが、残念ながら現実的ではありません。
ストレージに保存されているデータ量は非常に多く、新しいブロックが作られた際に、保管してある全てのブロックと比較するにはあまりにも膨大な処理量になってしまいます。
4-2 ハッシュ関数(チェックサム)で比較後、重複データを突き合わせて再度比較する方法
ハッシュ関数の一種であるチェックサムによって、比較データの母数を減らしてから、データ自体の突き合わせ判定を行う2段階方式で確認する方法です。
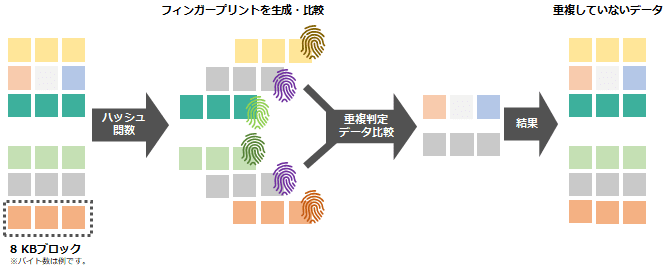
まず、ブロックを保管する際に、チェックサムを使ってデータの*フィンガープリントを作成しておきます。
フィンガープリントはデータよりもずっと小さいサイズ(数バイトから数十バイト程度)なので、ストレージに保管してあるすべてのブロックに関して比較することが非常に容易になり、判定が早くできます。
しかし、このチェックサムは、稀に異なるデータから同じフィンガープリントを生成することがあります(「ハッシュ値の衝突」ともいわれます)。実際は異なるデータなのに、フィンガープリントが一致して重複と判定され、どちらかが除外されてしまいます。そうすると、読みだした際にデータ化けが起こり、破壊されたように見えてしまいます。
その為、誤って重複と判断されたフィンガープリントが除外されないように、今度は、重複と判断されたフィンガープリント同士をデータに戻して、突き合わせて比較し最終確認を行います。
ただし、データ自体を突き合わせて比較する際は、ディスクアクセスやメモリ消費量が増え、ハードウェアのリソースを圧迫します。
*フィンガープリントとはデジタルコンテンツ(ここではデータブロック)をハッシュ関数で算出した値のことで、デジタルコンテンツの同一性を確認するために使用される。
ハッシュ値=フィンガープリント。主に、電子証明書や電子メール本文の改ざん確認、音楽やビデオ等の著作権侵害検出に使われる。
4-3 暗号学的ハッシュ関数で比較をする方法
暗号学的ハッシュ関数は、ハッシュ値の衝突の可能性を無視してよい確率まで低下させたフィンガープリントを、作成することができます。
その為、暗号学的ハッシュ関数によってフィンガープリントを作成・比較し、速やかに排除を行うことが可能です。
工数が限られている為、ハードウェアのリソース消費量が格段に少なくなるメリットがあります。
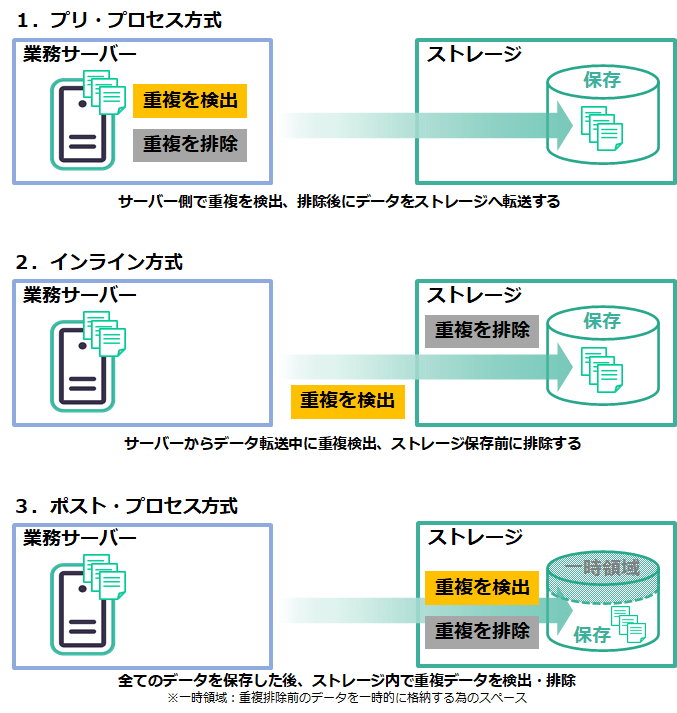
5.重複排除はソフトウェアかハードウェアで導入 ~3つの方式と推奨ケース例~
重複排除を採用するには実装されているバックアップソフトウェアか、ハードウェアを導入します。
重複排除は多くの場合、標準設定になってますが、手動で設定することもあるため、ベンダーに確認しましょう。
では、どちらがあなたの環境に適しているのでしょうか。
ソフトウェアかハードウェアかによって、重複の検出、排除を実行するタイミング別に3つの方式があります。
3つの方式の仕組みで、どのように異なるのか、それぞれ、どのようなメリットデメリットがあるのか見ていきましょう。
まずは、方式の図解説と推奨ケース例を交えたまとめの表をご覧ください。次に、方式別、ソフトウェアとハードウェアそれぞれの機能や特徴についてご説明いたします。
主な | 方式 | メリット | デメリット | 推奨ケース例 |
|---|---|---|---|---|
| ソフトウェア | 1.プリ・プロセス サーバー側で重複排除 | ● データ転送量の削減と転送性能の向上 ● 遠隔地転送において回線費用の削減 ● バックアップウィンドウの短縮 ● ストレージ容量効率がよい ● 汎用的なディスクストレージの利用可 | ● サーバー側に負荷がかかる ● システムパフォーマンス低下リスクあり ● CPUやメモリの追加が必要な場合もある | ● 遠隔地へ転送をする場合 ● LANやWANの環境を既存のまま利用する場合 |
| 2.インライン 転送中に重複検出 ストレージ側で排除して から保存 | ● サーバー側に負荷がかからない ● システムパフォーマンスを維持してバックアップ実行可能 ● ストレージ容量効率がよい ● 汎用的なディスクストレージの利用可 | ● メディアサーバーの設置が必要 ● 転送性能低下傾向にある・ストレージ側に負荷がかかる | ● システムパフォーマンスは既存のまま維持したい場合 ● 既存のストレージを活用したい場合 | |
| ハードウェア | ● サーバー側に負荷がかからない ● システムパフォーマンスを維持してバックアップ実行可能 ● ストレージ容量効率がよい ● 一般的なバックアップソフト利用可 | ● 転送性能低下傾向にある・ストレージ側に負荷がかかる ● 書き込みに時間がかかる可能性がある ● 専用のディスクストレージが必要 | ● システムパフォーマンスは既存のまま維持したい場合 ● 既存のバックアップソフトをそのまま使用したい場合 | |
| 3.ポスト・プロセス 全データをストレージに保管してから重複排除 | ● サーバー側に負荷がかからない ● システムパフォーマンスを維持してバックアップ実行可能 ● 書き込み速度は維持できる ● 一般的なバックアップソフト利用可 | ● 一時領域分のストレージ容量が必要(一時的に全データ格納用スペース) ● ストレージ側に負荷がかかる ● 転送性能に負荷がかかる ● 専用のディスクストレージが必要 | ● システムパフォーマンスは既存のまま維持したい場合 ● 既存のバックアップソフトをそのまま使用したい |
5-1 プリ・プロセス方式
業務サーバーにバックアップソフトウェアをインストールし、サーバー側で重複排除を実行した後にストレージへ転送し保存します。ストレージだけでなく、転送量も少なく抑えられるメリットがあり、特にフルバックアップのバックアップ時間を短縮できる効果があります。しかし、サーバーに負荷がかかるため、CPUやメモリなどの追加を必要とされる場合があります。
5-2 インライン方式
サーバーから転送中に重複データを検出し、ストレージに保存されるタイミングで排除します。ソフトウェアによるものと、ストレージ上のハードウェアによるもの2種類があります。
ソフトウェアの場合、メディアサーバーを設置し、重複排除に必要な負荷はメディアサーバー上のバックアップソフトで実行されるため、業務サーバーに余分な負荷をかけずに済みます。
ストレージ上のハードウェアによる重複排除は、ストレージに負荷がかかるため、書き込み速度が遅くなる傾向にあります。また、非常に高速な処理が求められることとなり、価格は高額になる可能性があります。
5-3 ポスト・プロセス方式
バックアップデータを一旦、ストレージに格納してから重複排除を実行します。
ストレージ上のハードウェアによるため、業務サーバーに負荷はかかりません。また、書き込み後に検出と排除を実行するので、インライン方式に比べて書き込み速度が向上します。しかし、全てのデータを一時的に格納しますから、比較的多くの容量を用意しておく必要があります。
5-4 『ソフトウェア』と『ハードウェア』で見るメリットとデメリット
実装元が・・ ソフトウェア
汎用的なディスクストレージに重複排除機能を取り入れることができるため、ストレージの自由度が高まります。
既存のストレージを流用でき、保守の観点からも既存の機器とメーカーを合わせることもできます。
メリット:データが格納されるストレージ装置を殆ど意識する必要がない
デメリット:アプリケーションの実行に影響を及ぼす恐れがある、または、メディアサーバーを用意する必要がある
実装元が・・ ハードウェア
バックアップ先として重複排除機能を搭載したストレージを採用します。
既存のバックアップ環境があれば、バックアップの運用を変更することなく、殆どの場合、現在使っているバックアップソフトをそのまま利用できます。
メリット:重複排除に必要な負荷はストレージで担い、業務サーバーに追加の負荷をかけない
デメリット:インライン方式では、金額が高額になる場合がある
本章では、重複排除の方式と実装元のメリットデメリットに加え、推奨ケース例をご案内いたしました。
一概に重複排除と言っても、ベンダーによって実現できる手法が異なります。インライン方式とポスト・プロセス方式を組み合わせた、ハイブリッド型や、ソフトウェアによってポスト・プロセス方式を実行する製品なども、近年登場しています。バックアップ先や、投資できる予算など、現在の環境に適切な方式を見極めたうえで、ソフトウェアやストレージを選定することをお勧めします。
注意:ソフトウェアとハードウェア両方での重複排除を実行することは、可能ですがあまりお勧めしません。
処理時間がかかる割に※効果が薄く、リストアの際にも通常より非常に時間がかかります。
その為、ソフトウェアかハードウェアどちらか一方で、重複排除を実行することをお勧めします。
※単位が異なる重複排除を行う場合は例外とします。(例:サーバーでファイル単位の重複排除後に、ストレージでブロック単位の重複排除)
6.重複排除と圧縮機能の併用でストレージ容量効率効さらにUP!
さて、ストレージ容量の利用効率をさらに高めるのが、「圧縮」機能との併用です。
圧縮もサーバーからデータを書き込む際に、小さなデータに分割してブロック単位で圧縮し、ストレージに保存するデータを小さくする機能です。その為、バックアップベンダーが提供する重複排除機能では、組み合わせて提供していることが多い技術です。
6-1 ソフトウェアとハードウェアによる「圧縮」の注意点
ソフトウェアによる圧縮とハードウェアによる圧縮の同時利用もできますが、圧縮効果が2倍になることはありません。バックアップに時間がかかったり、かえってデータ容量が増えてしまったりすることもあるので、お勧めしません。
| 実装元 | ソフトウェア | ハードウェア |
|---|---|---|
| 特徴 | 設定方法や圧縮率等は、使用するバックアップソフトウェアによって異なるため、ベンダーへの確認が必要。 | 一般的に、圧縮専用チップが搭載されているストレージを導入する。多くの場合デフォルトで圧縮機能が有効になっている。バックアップソフトウェアを利用することで無効にできる。 |
| 注意点 | CPUを利用して圧縮作業を行うため、業務で使用するタスクの処理速度低下の可能性がある。 | ストレージ装置によっては、重複排除機能と圧縮機能を同時に使用することができないことがある。 |
| 圧縮されたデータを読んだり変更したりする場合、圧縮解除と再圧縮が発生し、データアクセスによるパフォーマンス低下の可能性がある。 | データアクセスの際、圧縮解除と再圧縮を繰返すため、圧縮解除時にストレージの空き容量が減る。 |
6-2 バックアップでは「可逆圧縮」を使用 ~圧縮の主な形式のご紹介~
『圧縮』には、大きく分けて2種類あります。
① 可逆圧縮 完全に元の状態に戻す(解凍する)ことができる圧縮
② 非可逆圧縮 細部は戻せないが、情報全体の意味が変わらない圧縮
バックアップでは、データが完全に元の状態と等しくなる「可逆圧縮」が用いられます。
参考:日本アイアール株式会社様 記事コラムより
| データ圧縮 | 可逆圧縮 | ファイル圧縮 | zip、lzh、rarなど |
| 静止画圧縮 | JPEG2000、GIF、PNG、JBIGなど | ||
| 動画圧縮 | AMV Video Codec、Huffyuvなど | ||
| 音声圧縮 | WMA、DD+、Apple Losslessなど | ||
| 非可逆圧縮 | 静止画圧縮 | JPEG、JPEG XR、JPEG2000など | |
| 動画圧縮 | MPEG4、AV1、VP9など | ||
| 音声圧縮 | WMA、AC-3、MP3など |
7.Arcserve UDPによる重複排除効果事例とお勧め製品のご紹介
それでは、重複排除と圧縮がどのくらい効果があるものなのか、実際にArcserve UDPによる事例をもとにご紹介します。
7-1 重複排除と圧縮による効果事例のご紹介
効果事例 その1)霧島酒造株式会社様
バックアップ速度や、データ圧縮容量を実測値でご協力いただきました霧島酒造様の実証事例をご紹介します。
![]()
※詳細は『【Arcserve UDP 導入効果レポート】焼酎メーカー「霧島酒造」のITシステム環境のバックアッププ運用を実測データで紐解く』をご参照ください。
効果事例 その2)その他 5社
他にも導入経緯は一様ではありませんが、重複排除/圧縮効果をご紹介します。
| お客様名 | 導入製品 | バックアップ対象データ | ブロックサイズ | 重複排除 圧縮率 |
|---|---|---|---|---|
| ドン・キホーテ様 | Arcserve UDP Appliance (ハードウェア) | 資産管理システム | 推定4KB | 約 93% |
| 日本製鋼所様 | Arcserve UDP (ソフトウェア) | 3次元図面データ 製造に関わる資料動画など | 推定16KB | 約 59% |
| 光華女子学園様 | Arcserve UDP (ソフトウェア) | eラーニング用の 動画データや教務システム | 推定16KB | 約 44% |
| JBCC様 | Arcserve UDP Appliance (ハードウェア) | ファイル サーバー | 推定4KB | 約 38% |
| 江別市様 | Arcserve UDP Appliance (ハードウェア) | 仮想基盤 | 推定4KB | 約 60% |
重複排除/圧縮率が40%以上あれば、バックアップストレージ費用の節約はもちろん、環境によってはバックアップ時間や遠隔地へのレプリケート時間の短縮効果に期待できます。
7-2 重複排除は Arcserve UDP Appliance がお勧め
バックアップにはArcserve UDP Appliance (ハードウェア)がおすすめです。
Arcserve UDP Appliance(ハードウェア)なら、


従って、Arcserve UDP(ソフトウェア)をプリントインストールしたArcserve UDP Appliance(ハードウェア)なら、重複排除/圧縮での使い易さはもちろん、1つのコンソールですべてを管理できるため、大規模環境にもお勧めです。
Applianceに興味を持ったらこちらの資料もご参照ください。
>>> バックアップ アプライアンス Arcserve UDP 9000 シリーズのご紹介
Arcserve UDP(ソフトウェア)でも心配ご無用。事前確認用に必要スペックの計算方法を詳しくご案内しています。
>>> Arcserve Unified Data Protection 8.x サーバー構成とスペック見積もり方法
そして、実感してみてください。
>>> 30日間無料トライアル
まとめ
重複排除とは、データの中身を分析し、同じデータがあればそれを取り除く機能です。
バックアップでは、データ容量の削減を目的とし、ストレージコスト、バックアップ時間、回線圧迫回避の効果が期待できます。
その効果は大きく3つのポイントで異なります。
・重複排除の単位:ブロック単位が重複排除効果高め
・重複の判定方法:ハッシュ関数で判定を高速化・重複排除するタイミング:転送前ならバックアップ時間短縮と回線圧迫回避
圧縮との併用でストレージ容量削減効果は大きくなります。
注意すべきポイントは、サーバーのスペックとストレージ容量です。
重複排除の負荷を考慮してメモリやストレージ容量に余裕をもった見積もりが大切です。
導入するならソフトウェアかハードウェアか、環境に合わせて各社トライアルや効果事例も参考に選定ください。
ベンダーから製品説明を受けているときに、「あぁ、ここはあの方式ね~」と、思い出していただけると幸いです。













コメント